
人気のブレンドコーヒー「飲める文庫」で人工知能が果たした役割とは

ブレンドコーヒー「飲める文庫」。手前は6作品ドリップバックセット
人間が本を読んだときの「読後感」と「コーヒーの味」を、AI(人工知能)によって結びつけるというユニークな試みが行われた。日本電気株式会社(NEC)と、コーヒー豆専門店の株式会社 やなか珈琲(やなか珈琲店)が共同で開発した「飲める文庫」がそれだ。
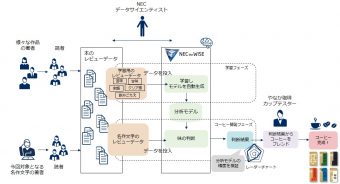
「飲める文庫」開発プロセス(NECプレスリリースより)
NECが名作文学の感想文をAIで解析し、その「読後感」をコーヒーの味覚指標(苦味/甘味/余韻/クリア感/飲みごたえ)としてアウトプットさせチャートを作成する。そのチャートに従って、やなか珈琲店のカップテスター(コーヒー豆の産地や銘柄に通じ、豆の風味や味わいを検査する専門職)がブレンドコーヒーを考案し「飲める文庫」と名付けた。
「飲める文庫」は、やなか珈琲店の店舗で販売され、当初用意した500kgが完売、急遽増産したほど反響があったという。
この「飲める文庫」の開発過程や今後の展開について、NECの茂木崇氏(AIプロモーション担当)とやなか珈琲店の大関慧氏に聞いた。
* * *
――開発工程の最初のステップでは、データサイエンティストが文学作品に関するレビュー文を1万件以上も読み、文章の内容をコーヒーの味覚指標に変換したとリリースにありましたが、1万件以上ものレビュー文をどうやって集めたのでしょう。

NECの茂木崇氏
茂木:ウェブアンケートを実施して、文学作品を中心にレビューデータを集めました。
――そのレビュー文をコーヒーの味覚指標に変換していくときは、どのような基準で?
茂木:データサイエンティストたちが議論して、なるべく違和感のないように変換することを心掛けました。たとえば、恋愛小説を読んで「青春時代の懐かしさを感じた」とあれば、甘味の指標を増やす。あるいは、「悲しい結末で胸が苦しくなった」とあれば、苦味を増やす。「テンポよく爽快で一気に読めた」など読みやすさについて書かれていれば、すっきり飲めるイメージと紐づけ、クリア感を増やすといった具合です。人間が感想を述べる際に、こうした味覚に近い表現をすることに着目したわけです。ちなみに、今は説明のためにわかりやすい言葉で伝えましたが、レビュー文にはもっといろいろな表現がありますから、データサイエンティストが1万件以上のレビュー文をひとつひとつ読み込む必要があります。5、6人が担当して、1カ月ほどかかったでしょうか。
――最初のステップで、テキスト分析技術などを使わず、人が変換したことには理由があるんですか。
茂木:今回、名作文学の分析に使ったソフトウェア「NEC Advanced Analytics – RAPID機械学習(以下、RAPID機械学習)」は、ディープラーニング(深層学習)技術を搭載したものです。ディープラーニングは人の脳を模したAI技術で、人の感覚や嗜好に近い判断ができるとも言えます。ですから、まずデータサイエンティストにレビュー文をコーヒーの味に変換してもらい、その変換過程をAIに学んでもらおうと考えたのです。ちなみに、今回よくあったのが、「AIが人の味覚や感想文の内容を理解するんですか」といった質問です。実はそうではなくて、今回AIがしているのは「人の判断の真似」です。ですから、AIが味覚を学んだり、文章の内容を理解したりしているわけではありません。
■「AIは橋渡し役、あくまで主役は人間です」
――開発過程で、AIは具体的に何をしたのでしょう。
茂木:データサイエンティストが作った大量の学習データを、RAPID機械学習エンジン(AI:画像・テキストなど非構造化データに対応した高速・軽量なNECの機械学習アプリケーション)に投入して、レビュー文をコーヒーの味覚指標に変換する「分析モデル」(人間の脳でいう神経回路)を作らせました。そこに、夏目漱石の『吾輩は猫である』や太宰治の『人間失格』など6つの名作文学のレビュー文を投入し、それぞれの味のチャートを作らせました。
――この後はやなか珈琲店にバトンタッチするわけですね。カップテスターが受け取ったのは味のチャートだけですか。ほかにAIから情報は?
大関:いえ、チャートだけです。それを元に豆を組み合わせ、焙煎の時間などを計算し、チャート通りになるようなブレンドコーヒーを作りました。

やなか珈琲店の大関慧氏
茂木:AIは変換をしただけです。データサイエンティストが頑張ったことと、やなか珈琲店様のクリエイティブな商品作りの橋渡しをしただけです。いってみれば裏方ですね。AIが橋渡しをした後は、やなか珈琲店のカップテスターさんが文学作品の背景なども加味しながら味を調整してくれました。
大関: おかげさまで反響も上々で、本好きや最先端技術が好きな人など客の層が広がった感じがあります。
■「分析対象がレビュー」だからこそ広がる可能性
――今回はAIに本そのものではなくレビューを読ませたわけです。なぜ「本の内容」ではなく「読後感」だったのでしょう。
茂木:コーヒーの味というのは、飲んだ人が感じることで、あくまでその人の感想ですよね。ですから、本を読んだ人の感想の方が、味わいの表現に近くなるだろうと考えたんです。また、AIはたくさんのデータを学習させれば学習させるだけかしこくなりますが、これから世の中でデータとしてどんどん増えていくのは、作品の本文よりもレビューデータです。ですから、今後のことも考えて、本文そのものの内容ではなく、あえて読後感とコーヒーの味を結びつけることにしました。
――「今後のこと」という言葉が出ましたが、これから何か広がる可能性があるのでしょうか。
茂木:今回は本のレビューでしたが、人は絵画や映画、家電などいろいろなものに感想を抱きます。それを他のものに対する感覚や嗜好に結びつけることができないかと考えています。それは例えば、映画と食べ物の味かもしれませんし、音楽と触覚かもしれません。あるいはソファーなどの座り心地と飲み物かもしれない。そうした人間の感覚を、他のものと結びつけることで、新しいマーケティングやビジネスが生まれるのではないかと考えているところです。
茂木氏によると、NECはクリエイティブな人間の判断や行動を“発展途上なAI”にサポートさせ、実社会の課題解決や事業創出を目指しているという。今回AIは、NECのデータサイエンティストというある意味プロ職人の解析のサポート役であり、その解析チャートがやなか珈琲店というプロ職人の手に渡り、画期的な製品を生み出した。
今回、AIの役割はまさに、プロ職人のサポート役だったわけだ。「職人から職人へAIが橋渡し」した事例として注目したい。
関連記事









