
【日本人が知らない 、世界のスゴいスタートアップ Vol.21】AIがもたらす文化喪失危機、国産モデルが必要な理由

イメージ図(記事本文とは関係ありません)
連載「日本人が知らない、世界のスゴいスタートアップ」では、海外のベンチャー投資家やジャーナリストの視点で、日本国内からでは気付きにくい、世界の最新スタートアップ事情、テック・トレンド、ユニークな企業を紹介していきます。今回のテーマは、「主権と文化は国産AIで守れ」です。(聞き手・執筆:高口康太)
* * *
AI(人工知能)は仕事に欠かせないツールとなった。メインで使っているのはグーグルのジェミニだが、アリババのQwen(クウェン)も併用している。というのも、私は中国の経済や企業、テックについて取材、執筆するジャーナリストなのだが、米国企業のAIに中国に関してのリサーチや語句の説明を頼んでも的外れな返答が返ってくることが多い。中国のAIにたずねると、「中国政府の正式見解」のような回答に閉口することもあるが、だいたいは中国の肌感に合う答えが返ってくる。
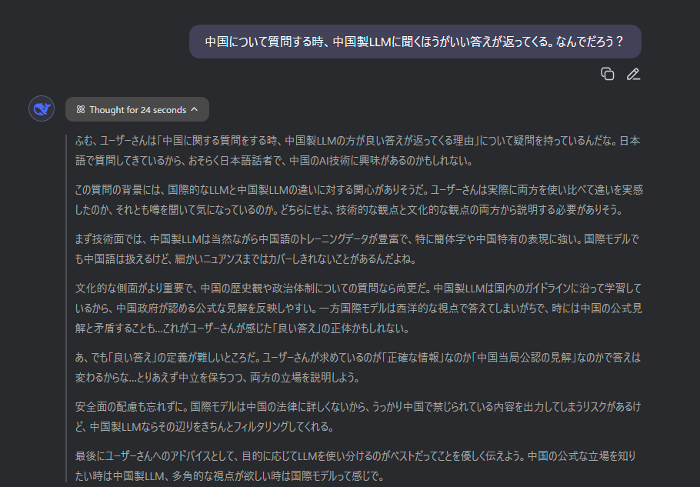
*ディープシークにこの問題についての見解を尋ねた結果(下の画像)。中国製AIには中国語の学習データが豊富という長所がある上に、中国政府のガイドラインに従っているので、“うっかり違法な答え”を返す心配がないというメリット(?)もあるという。
米中AIの使い分けをやっていると、ちょっと気になるのが「日本のことを知りたい時に、米国のAIを使うことでいいのかな」ということ。「サイバー万里の長城」(中国政府が築いた検閲システムを指すネットスラング)の向こう側にある中国はともかく、同盟国・日本のことは米国製AIもわかってくれているのだろうか。それとも日本の実情に即したAIを日本独自でがんばって開発するべきなのだろうか。
最新の技術トレンドに詳しい、台湾の投資家マット・チェン氏に話を聞いた。
鄭博仁(マット・チェン、Matt Cheng) ベンチャーキャピタル・心元資本(チェルビック・ベンチャーズ)の創業パートナー。創業初期をサポートするエンジェル投資の専門家として、物流テックのFlexport、後払いサービスのPaidyなど、これまでに15社ものユニコーン企業に投資してきた。元テニスプレーヤーから連続起業家に転身。ジョインしたティエング・インタラクティブ・ホールディングス、91APPは上場し、イグジットを果たしている。
* * *
――米大企業がしのぎをけずるチャット型AIの開発。その賢さには驚かされるばかりですが、米国以外、英語圏以外のトピックではいまいちな回答が多いようですが。
マット・チェン(以下、M): 先日、日本で起業している外国人経営者と会ったのですが、彼が言うには日本市場へのアジャストよりも、日本のコミュニケーションを理解するほうに時間がかかったそうです。敬意のこもった対話が続いても、それが合意に近いサインなのか、婉曲的な拒絶なのかよくわからなかったとか。「担当者をご紹介ください」とメールしたら、「考えさせてください」との返信だけで連絡が途絶えたとか。考えがまとまったら、イエスかノーの返事が来るものだと思っていたがと苦笑していました。
――「空気を読め」というやつですね。
M:こうした文化の差はチャット型AIに使われているLLM(大規模言語モデル)にも関係します。自然文での対話を円滑に行うためには文脈や暗黙の了解を理解することが必要だからです。今の主要AIの多くは英語の文脈で訓練されています。そうしたAIは日本をはじめとする非英語圏の文脈を本当に理解できるのか。
AI研究者もこの問題を認識しています。MITスローン経営大学院の研究チームが発表した論文「Cultural tendencies in generative AI」(生成AIにおける文化的傾向)は興味深いものでした。オープンAIのチャットGPTと中国検索大手バイドゥのAI「アーニー」に、英語で100問、中国語で100問の同じ質問を投げかけたのですが、言語による違いは明らかでした。
たとえば保険の広告コピーをAIに考えさせる時、英語で質問すると「あなたの未来、あなたの安心」といった具合に個人をフォーカスした回答が返ってきます。中国語では「家族の未来はあなたの約束」といった、個人ではなく集団や社会、国を強調する内容が回答される傾向が明らかになりました。
――質問された言語に応じて、AIが回答に利用する「暗黙の了解」を切り換えている、と。
M:質問した言語ごとに回答の文化的傾向が異なることにほとんどのユーザーは気づいていません。仕事から生活まで、さまざまなシーンでAIを頼りにする人は増えています。AIの持つ文化的傾向が拡散し、社会に浸透していく可能性は高いでしょう。AIを使っていない人も無縁ではありません。私たちが日々目にするテレビ番組や新聞記事、あるいは教科書も作成過程でAIが使われていることが増えているからです。
前述の論文は、質問する言語に応じた文化的傾向という内容でしたが、おそらくAIモデルごとにも異なる文化的傾向があるでしょう。中国語中心で学習している中国企業のAIは、英語や日本語で質問されても中国的な文脈で返答する可能性が高いのではないでしょうか。同様に、英語中心で学習したAIも、他言語で質問されても英語圏の文化的な文脈で回答する可能性が高いのです。
日本をはじめとする、自国開発の主要AIを持っていない国は、AIを通じた海外からの文化的浸透にさらされているというリスクが浮上しているのです。
国産AIが必要な理由
――海外のAIにお金を払うことで生じる「デジタル赤字」は注目を集めるようになりましたが、文化を失うリスクがあるというのは知られていませんね。
M:どのような影響、リスクがあるのかは今後さらに研究が必要となりますが、リスク回避の動きは始まっています。国家が監督するAIガバナンスや、海外に依存しない国産AI、いわゆるソブリンAI(Sovereign AI)を開発する動きが始まっています。
AIガバナンスでは欧州連合(EU)のAI法が代表例です。特に注目すべきは開発者に対して学習データの開示を義務づけた点です。これによりそのAIがどのような文化的背景や価値を持っているのかを可視化しようとする試みです。
ソブリンAIの開発も加速しています。シンガポールは東南アジアの言語と文化的背景に特化したオープンソースLLM「シーライオン」を開発しています。サウジアラビアは政府系ファンドを通じて1000億ドルもの資金を投資し、大規模データセンターやAIの研究開発を進めています。
――AI開発は米中が大きくリードしており、別の国が今から追いつくことは難しいのでは。
M:LLMはたんなるアルゴリズムではなく、文化的価値や情報ガバナンス、国家安全保障に関わるもの。すなわち、他国で訓練されたAIに長期的に依存すれば、私たちは文化的背景や思考法まで失う可能性があるのです。追いつき追い越すのは難しくとも、自国のAIという選択肢を持っておく必要があるのです。
――商売にはならないが、安全保障のためにはやるしかない、と。AI開発には多くの資金が必要ですが、ビジネス的には厳しいとなると税金を使って実施することになるのでしょうか。
M:国の支援は必要でしょうが、企業ビジネスとして成功する余地も十分にあるでしょう。
私が注目しているのは、「Shisa.ai」という東京のスタートアップです。連続起業家のシェン・ジアCEO、レオナルド・リィンCTO、AIリサーチャーのアダム・レンセンメイヤー、3人の外国人起業家で設立された会社です。ラマやミストラルなどのオープンソースAIに日本語学習データセットなどで追加学習を行う二次開発によって、GPT-4oやDeepSeek-V3に匹敵するAIを構築しています。
新エネルギー・産業技術総合開発機構(NEDO)が実施している、「GENIAC-PRIZE」という生成AIアプリケーションの募集プロジェクトでも、AIエージェントを動かす日本国産基盤モデルの一つに選ばれ、「Shisa-v2の 405Bモデルは、2025年6月6日現在、国内でトレーニングされたモデルの中で最高のベンチマークスコアを達成」と評価されています。
なぜ、外国人3人が日本に定住し起業する道を選んだのでしょうか。彼らはローカルから立ち上げたAI主権が必要だと確信しています。言語と文化の多様性を保存し、データプライバシーや地政学的なレジリエンス、国家のデジタル主権に関わる問題を解決するためには各国ごとに開発されたAIが必要である、と。特にアダムは日本のアニメ作品の英語字幕翻訳家として活躍した経歴もあり、日本語のニュアンスや文化の表現をどうAIに理解させるのかという課題におけるキーパーソンです。
日本政府も積極的に支援しています。経済産業省は2024年にAI開発支援プロジェクトの「Generative AI Accelerator Challenge(GENIAC)」を立ち上げました。資金や計算能力、そしてメンターなどのリソースを提供しています。
ローカルAIのビジネス需要
M:一方で、企業レベル、民間レベルでもローカルAIの需要が生まれる可能性があります。AIの開発にはデータが必要です。インターネット時代になってからの30年間にウェブに蓄積されたデータが利用されてきました。しかし、これらはほとんど利用され尽くしたため、学習データの不足が始まろうとしています。
――新たなデータの収集源として、現実世界が注目されているというお話も以前にうかがいました(シンギュラリティのためには、AIに身体が必要な理由)
M:Shisa.aiのシェン・ジア氏は未来のブレークスルーは「より多くのデータ」にあるのではなく、「より文脈に寄り添ったデータ」だと予測しています。たとえば、ウェブ上に自動的に残らないような声や感情。高齢者の日常会話、地方の方言、Z世代のデートにおける口調の変化など、言語と文化が交差するリアルな学習データを掌握する者が、次世代モデルの切り札を握ると見ているのです。
これらのデータを収集するためにはローカルな開発と、ローカルな社会実装が必要です。Shisa.aiはすでにレストランでの外国人対応、小売店舗の返品交換処理のサポート、駅の多言語対応道案内といったサービスを展開しています。こうした社会実装は、ローカルなデータを収集するための第一歩です。将来的には、ユーザーの許諾を得た上で、より多様でパーソナルな領域のデータ収集へと繋げていく構想なのでしょう。
――現実の利用事例から、その国に合わせたデータが蓄積され、文化に根ざしたAIが生まれる、と。
M:利用者の側に立ってみれば、暗黙の前提を共有してくれるAIのほうが使い勝手がいいでしょう。外国人とのコミュニケーションのように細かく指示したり前提を確認したりしないとならないAIよりも、語らずとも暗黙の前提を理解してくれるAIのほうが利用のハードルが低い。
Shisa.aiの取り組みはまだ始まったばかりですが、今後AIの開発と実装が進むにつれ、こうしたソブリンAIの開発は加速していくはずです。AIを使う頻度は今後増える一方ですが、AIの言葉が私たちに深く影響するようになれば、世界の最先端のAIよりも、文化を共有しているAIを選択したいというケースは増えていくでしょう。
言葉はたんなるツールではなく、文化を内包したコンテナです。AIによって私たちの文化が影響を受けるのではなく、私たちの言葉によってAIがどう世界を理解するかを決定するようにしなければならないのです。
* * *
チャットGPTの登場からしばらくは性能の進化が最大の注目点だった。だが、AIの性能がかなり高度に進化した今は、性能よりも別のポイントが重要になってきている。ユーザーインターフェースの善し悪し、スマホからアクセスできるか、データ保護の厳格さ、自律的な判断や行動が可能か……などなど。
そうした判断要素の一つに、私たちの考え方や文化にどれだけ適合的かという点も含まれていくのだろう。それはAI時代にあわせて人間や社会が変わることも必要だが、変えてはいけないものをどう守るかという問いにもつながっている。
関連記事









