


近年、振り込め詐欺などの特殊詐欺は、認知件数、被害総額ともに減少傾向にあるとはいうものの、その被害総額は300億円を超えるなど、依然として深刻な状況にある。
このような金融犯罪を防ぐため、多くの金融機関では、AI(人工知能)を活用して、不正取引を自動検知するシステムの導入を検討している。AIの学習には大量の学習データが必要になるが、取引データには口座番号等の個人情報が含まれるため、他の銀行のデータを利用する事ができず、学習データとして利用できる十分な量の取引データを用意するのが難しかった。こうしたシステムの検知精度は、学習するデータの量に依存してしまうため、現在の機械学習技術では高い精度を実現することができていない。
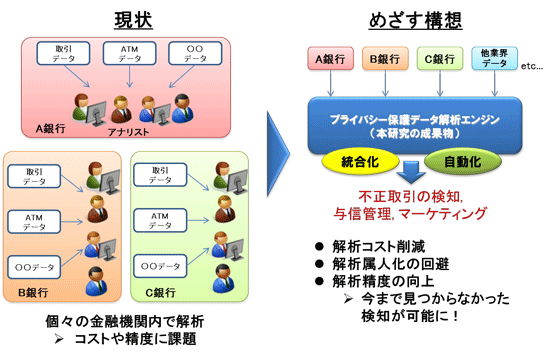
こうした課題を解決するため、国立研究開発法人情報通信研究機構(NICT)サイバーセキュリティ研究所セキュリティ基盤研究室と、国立大学法人神戸大学、株式会社エルテスが取り組んでいるのが、「プライバシー保護深層学習技術(Deep Protect)」を活用した不正送金検知の実証実験(※)だ。
※ JST CREST「人工知能」領域の研究課題「プライバシー保護データ解析技術の社会実装」の一環として行われている
プライバシー保護深層学習技術とは、NICTが独自開発している技術。暗号技術と深層学習(ディープラーニング)技術を融合することで、金融機関が持つ取引データを外部に開示することなく、複数の金融機関が連携して機械学習を行うことができる。
現在この実証実験は、金融機関5行(千葉銀行、三菱UFJ銀行、中国銀行、三井住友信託銀行、伊予銀行)とともに行われており、2021年度末までに、複数金融機関による協調学習が可能となるシステムを構築しようとしている。
プライバシー保護深層学習技術の仕組みや今後の展望について、NICTサイバーセキュリティ研究所セキュリティ基盤研究室の野島良室長に聞いた。
暗号化したまま機械学習
「プライバシー保護深層学習技術」の仕組みはどのようになっているのだろう。
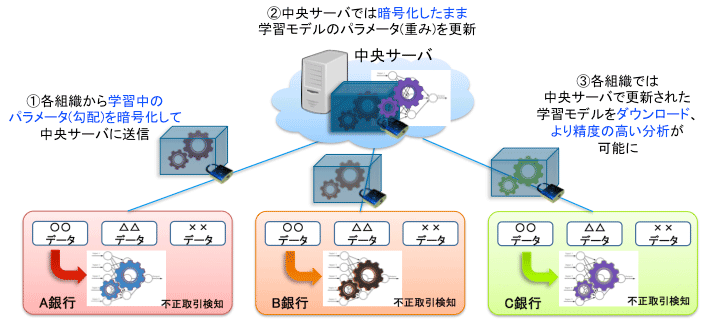
実証実験の大まかな流れはこうだ。まず各銀行の持つ情報(学習中のパラメータ〈勾配〉)を暗号化し、中央サーバーに集める。中央サーバーでは、集めた情報をもとに、暗号化したまま学習モデル(パラメータ〈重み〉)を更新する。その学習モデルを各銀行がダウンロードする。
「これにより、中央サーバーでは、銀行の取引データをもらっていないのに、あたかも複数の銀行の取引データを使って機械学習したかのような結果が得られます。一方、各銀行側は、情報漏洩の危険を避けつつ、他銀行のデータも含めた学習モデルが得られ、より精度高く不正取引を自動検知できるようになります」(野島氏)
ではプライバシー保護深層学習技術では、なぜデータを隠したまま機械学習ができるのか。
野島氏によると、基本的に機械学習とは、目的に見合ったある種のプログラム(関数)を作る作業だという。このプログラムの中で使われる、より最適な数値(パラメーター)を算出していくことが、すなわち学習モデルを更新することになる。
「たとえば、『Ax+B』(「x」は実際に分析をするときの変数「特徴量」)というプログラムを作りたいとします。機械学習とは端的にいうと、このAやBの最適なパラメーター(数値)を探し出す処理のことをいいます」
最適なパラメーターを見つけるためには「勾配情報」というものが必要となる。プライバシー保護深層学習技術では、「確率勾配降下法」と呼ばれる機械学習の手法が用いられているが、その様子をグラフにすると、下の立体図になる。この図の底の部分が最適なプログラム、すなわち最適な学習モデルということになり、勾配情報とはこの底に向かうための傾き度合いを示す数値のことだ。

「各銀行では、機械学習を行いながら『右へ10』『左へ−30』といった勾配情報をどんどん算出しています。プライバシー保護深層学習技術では、この勾配情報を暗号化し、中央サーバーに集めています。これらを加算していくことで、一番低いところ(最適な学習モデル)に向かおうというわけです」
通常、データを暗号化してしまうと、そのままでは計算処理が出来ないが、このプライバシー保護深層学習技術では、暗号のまま加算できる「加法準同型暗号」という暗号を使っている。
「各銀行から勾配情報が暗号化され送られてくるのですが、暗号化したまま復号せずに加算できる暗号技術(「加法準同型暗号」)が使われているため、中央サーバー上で加算した勾配情報をもとに各銀行の学習モデルを更新できます。実はすごくシンプルな仕組みになっているのです」
金融以外の分野でも
複数の銀行と実証実験を行うことで「実用化に向けた課題も見えてきた」と野島氏は続ける。
「銀行によってデータの粒度やフォーマットがまちまちであるため、AIにデータを分析させる前の前処理が大変だということがわかってきました。もともと銀行のデータは、プライバシー保護深層学習技術のような協調学習を想定していないので、これは当然のことではあります。銀行内の処理としての課題ではなく、我々のプロジェクトを遂行するうえでの課題ということですね」
社会実装のプロセスについては、NICTは公的な研究機関であるため製品開発をすることまではできないが、「連携する民間企業に製品、事業として展開する部分を担ってもらおうと考えている」と述べた。
さらに野島氏は、「この実証実験は不正送金の自動検知に限る話ではない」と今後はさらに、別の分野でも利用できると強調した。
「例えば医療機関が持つ情報の共有など、複数の組織間でデータを共有して学習するという用途であれば、ほぼ何でも活用できます。今まで組織の外に出せなかったような機微な情報を横断的に共有し学習することで、新たな価値を創造する。分野を問わず、そういった用途にどんどん活用できればと考えています」